Mehrsprachige Kundensupport-Tickets (Synthetisch)
Ein vollständig synthetischer Datensatz zum Trainieren und Evaluieren von Helpdesk-Modellen, wie der Klassifizierung von Warteschlange, Priorität und Typ, sowie für das Pre-Training von Antwortassistenten. Erstellt mit unserem Python Synthetic Data Generator und auf Kaggle veröffentlicht.
- Kaggle: Ticket-Datensatz
- Synthetische Datengenerierung (geplant LGPL)
- Benötigen Sie benutzerdefinierte Daten oder das Tool? sales@softoft.de
Versionen im Überblick

| Version | Sprachen | Größe (relativ) | Anmerkungen |
|---|---|---|---|
| v5 | EN, DE | Größte | Neueste und verfeinerte Taxonomie/Balancing; Fokus auf EN/DE-Qualität. |
| v4 | EN, DE | Groß | Ähnlicher Fokus wie v5; etwas ältere Prompts und Verteilungen. |
| v3 | EN, DE, + mehr (FR/ES/PT) | Kleiner | Frühere Pipeline; mehr Sprachen, aber insgesamt weniger vielfältiger Inhalt. |
Ältere Versionen enthalten mehr Sprachen, sind aber im Allgemeinen kleiner und weniger vielfältig. Die neuesten Versionen (v5, v4) legen den Schwerpunkt auf EN/DE-Qualität und -Umfang.
Welche Version sollte ich verwenden?
- Training von EN/DE-Produktionsmodellen → beginnen Sie mit v5 (oder v4, wenn Sie einen vergleichbaren älteren Satz benötigen).
- Forschung über mehrere Sprachen hinweg → v3 (kleiner, aber enthält mehr Locales).
Dateien & Benennung
Sie finden CSV-Exporte pro Version (Beispiele):
dataset-tickets-multi-lang-4-20k.csv
dataset-tickets-multi-lang3-4k.csv
dataset-tickets-german_normalized.csvSchema
Jedes Ticket enthält den Kerntext sowie Labels, die von Open Ticket AI verwendet werden.
| Spalte | Beschreibung |
|---|---|
subject | Der E-Mail-Betreff des Kunden |
body | Der E-Mail-Text des Kunden |
answer | Die erste Antwort des Agenten (KI-generiert) |
type | Ticket-Typ (z.B. Incident, Request, Problem, …) |
queue | Ziel-Warteschlange (z.B. Technical Support, Billing) |
priority | Priorität (z.B. low, medium, high) |
language | Ticket-Sprache (z.B. en, de, …) |
version | Datensatzversion (Metadaten) |
tag_1, tag_2, … | Ein oder mehrere thematische Tags (können teilweise null sein) |
Ausschnitte aus den Daten
de (Incident / Technical Support / high)Betreff: Wesentlicher Sicherheitsvorfall Text (Auszug): „…ich möchte einen gravierenden Sicherheitsvorfall melden…“ Antwort (Auszug): „Vielen Dank für die Meldung…“
en (Incident / Technical Support / high)Betreff: Account Disruption Text (Auszug): “I am writing to report a significant problem with the centralized account…” Antwort (Auszug): “We are aware of the outage…”
en (Request / Returns and Exchanges / medium)Betreff: Query About Smart Home System Integration Features Text (Auszug): “I am reaching out to request details about…” Antwort (Auszug): “Our products support…”
Visueller Rundgang
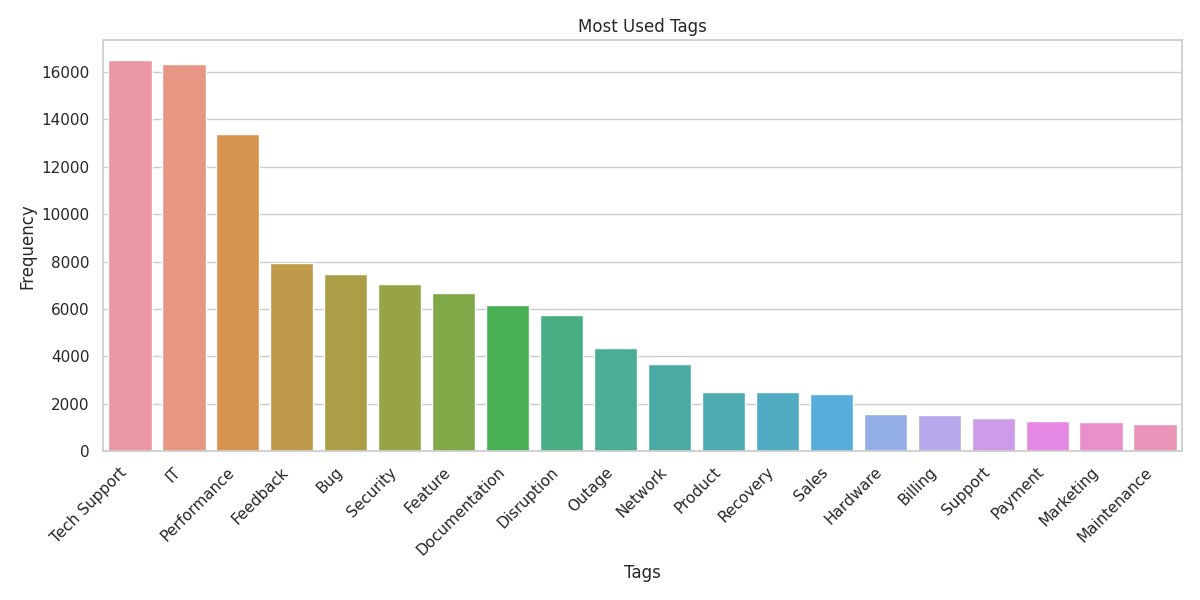
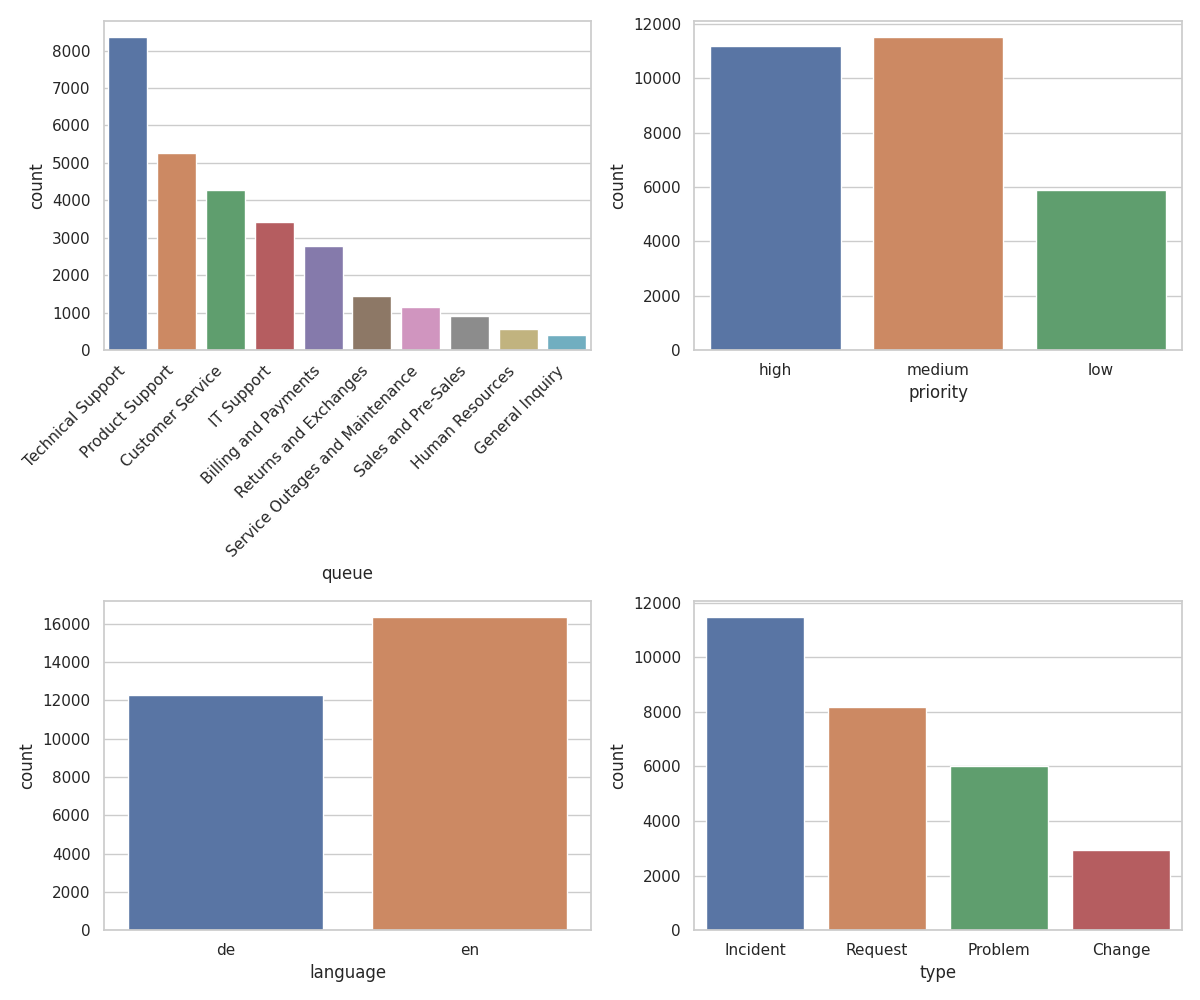
Verwendungszweck & Einschränkungen
Verwendungszweck:
- Kaltstart-Training von Modellen für Warteschlange/Priorität/Typ
- Experimente zum Class-Balancing
- Mehrsprachiges Benchmarking (verwenden Sie v3, wenn Sie FR/ES/PT benötigen)
Einschränkungen:
- Synthetische Verteilungen können von Ihrem Produktions-Traffic abweichen. Validieren Sie immer mit einer kleinen, anonymisierten realen Stichprobe vor dem Deployment.
Laden & schnelle Überprüfungen
import pandas as pd
df = pd.read_csv("dataset-tickets-multi-lang-4-20k.csv") # oder Ihre gewählte Version
# Grundlegende Plausibilitätsprüfungen
print(df.language.value_counts())
print(df.queue.value_counts().head())
# Einfachen Text für die Klassifizierung vorbereiten
X = (df["subject"].fillna("") + "\n\n" + df["body"].fillna("")).astype(str)
y = df["queue"].astype(str)Beziehung zu Open Ticket AI
Dieser Datensatz spiegelt die Labels wider, die Open Ticket AI für eingehende Tickets vorhersagt (Warteschlange, Priorität, Typ, Tags). Verwenden Sie ihn, um das Training und die Evaluierung zu bootstrappen; deployen Sie Ihr Modell mit Open Ticket AI, sobald Sie mit den Metriken zufrieden sind.
Lizenz & Zitat
- Datensatz: Bitte fügen Sie hier Ihre gewählte Datenlizenz ein (z.B. CC BY 4.0).
- Generator: geplant LGPL. Für Zugriff oder Anpassungen: sales@softoft.de.
Zitiervorschlag:
Bueck, T. (2025). Multilingual Customer Support Tickets (Synthetic). Kaggle Dataset. Generated with the Open Ticket AI Synthetic Data Generator.
Changelog (Übersicht)
- v5: Nur EN/DE; größter Satz; verbesserte Taxonomie und Balancing.
- v4: EN/DE; groß; früherer Satz von Prompts.
- v3: Kleiner; enthält zusätzliche Sprachen (FR/ES/PT), frühere Pipeline.