Tickets de Soporte al Cliente Multilingües (Sintéticos)
Un conjunto de datos totalmente sintético para entrenar y evaluar modelos de asistencia técnica como la clasificación de cola, prioridad y tipo, además del preentrenamiento para la asistencia en respuestas. Creado con nuestro Generador de Datos Sintéticos en Python y publicado en Kaggle.
- Kaggle: Conjunto de Datos de Tickets
- Generación de Datos Sintéticos (LGPL planificada)
- ¿Necesitas datos personalizados o la herramienta? sales@softoft.de
Versiones de un vistazo

| Versión | Idiomas | Tamaño (relativo) | Notas |
|---|---|---|---|
| v5 | EN, DE | El más grande | Taxonomía/balanceo más reciente y refinado; se enfoca en la calidad de EN/DE. |
| v4 | EN, DE | Grande | Enfoque similar a v5; prompts y distribuciones ligeramente más antiguos. |
| v3 | EN, DE, + más (FR/ES/PT) | Más pequeño | Pipeline anterior; más idiomas pero contenido menos diverso en general. |
Las versiones más antiguas incluyen más idiomas, pero generalmente son más pequeñas y menos diversas. Las versiones más nuevas (v5, v4) enfatizan la calidad y la escala de EN/DE.
¿Qué versión debería usar?
- Para entrenar modelos de producción EN/DE → comienza con v5 (o v4 si necesitas un conjunto comparable más antiguo).
- Para investigación en múltiples idiomas → v3 (más pequeño, pero incluye más localizaciones).
Archivos y nomenclatura
Encontrarás exportaciones CSV por versión (ejemplos):
dataset-tickets-multi-lang-4-20k.csv
dataset-tickets-multi-lang3-4k.csv
dataset-tickets-german_normalized.csvEsquema
Cada ticket incluye el texto principal más las etiquetas utilizadas por Open Ticket AI.
| Columna | Descripción |
|---|---|
subject | El asunto del correo electrónico del cliente |
body | El cuerpo del correo electrónico del cliente |
answer | La primera respuesta del agente (generada por IA) |
type | Tipo de ticket (ej. Incidente, Solicitud, Problema, …) |
queue | Cola de destino (ej. Soporte Técnico, Facturación) |
priority | Prioridad (ej. baja, media, alta) |
language | Idioma del ticket (ej. en, de, …) |
version | Versión del conjunto de datos (metadatos) |
tag_1, tag_2, … | Una o más etiquetas temáticas (pueden ser null en algunos casos) |
Fragmentos de los datos
de (Incidente / Soporte Técnico / alta)Asunto: Wesentlicher Sicherheitsvorfall Cuerpo (extracto): „…ich möchte einen gravierenden Sicherheitsvorfall melden…“ Respuesta (extracto): „Vielen Dank für die Meldung…“
en (Incidente / Soporte Técnico / alta)Asunto: Account Disruption Cuerpo (extracto): “I am writing to report a significant problem with the centralized account…” Respuesta (extracto): “We are aware of the outage…”
en (Solicitud / Devoluciones y Cambios / media)Asunto: Query About Smart Home System Integration Features Cuerpo (extracto): “I am reaching out to request details about…” Respuesta (extracto): “Our products support…”
Recorrido visual
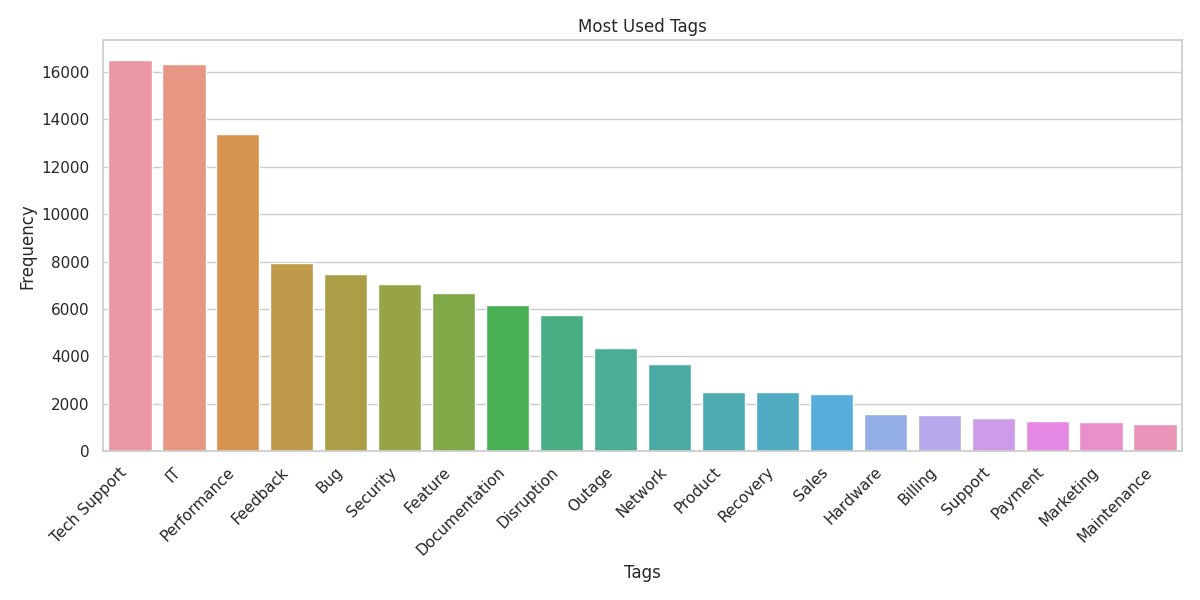
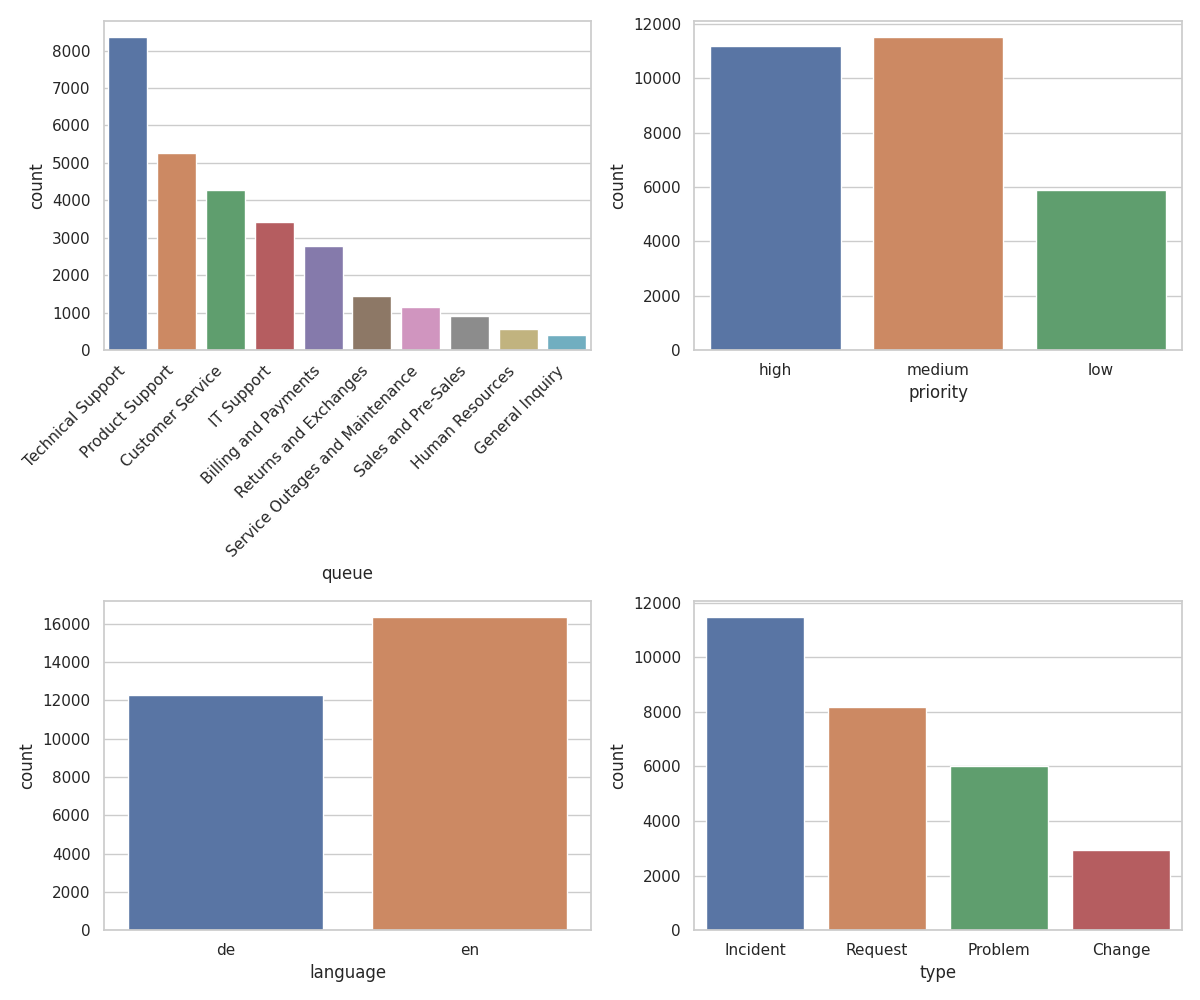
Uso previsto y limitaciones
Uso previsto:
- Entrenamiento de modelos desde cero para cola/prioridad/tipo
- Experimentos de balanceo de clases
- Benchmarking multilingüe (usa v3 si necesitas FR/ES/PT)
Limitaciones:
- Las distribuciones sintéticas pueden diferir del tráfico de tu entorno de producción. Valida siempre con una muestra real, pequeña y anonimizada antes de desplegar.
Cómo cargar y verificaciones rápidas
import pandas as pd
df = pd.read_csv("dataset-tickets-multi-lang-4-20k.csv") # or your chosen version
# Basic sanity checks
print(df.language.value_counts())
print(df.queue.value_counts().head())
# Prepare simple text for classification
X = (df["subject"].fillna("") + "\n\n" + df["body"].fillna("")).astype(str)
y = df["queue"].astype(str)Relación con Open Ticket AI
Este conjunto de datos refleja las etiquetas que Open Ticket AI predice en los tickets entrantes (cola, prioridad, tipo, etiquetas). Úsalo para iniciar el entrenamiento y la evaluación; despliega tu modelo con Open Ticket AI una vez que estés satisfecho con las métricas.
Licencia y citación
- Conjunto de datos: por favor, añade aquí la licencia de datos que elijas (p. ej., CC BY 4.0).
- Generador: LGPL planificada. Para acceso o personalizaciones: sales@softoft.de.
Citación sugerida:
Bueck, T. (2025). Multilingual Customer Support Tickets (Synthetic). Kaggle Dataset. Generado con el Generador de Datos Sintéticos de Open Ticket AI.
Changelog (alto nivel)
- v5: Solo EN/DE; el conjunto más grande; taxonomía y balanceo mejorados.
- v4: EN/DE; grande; conjunto de prompts anterior.
- v3: Más pequeño; incluye idiomas adicionales (FR/ES/PT), pipeline anterior.